近日,学院3篇论文被ACL2025主会与Findings录用,其中主会论文1篇,Findings论文2篇,论文涉及关系提取样本生成、脑认知研究领域。3篇论文作者均来自学院“NUAA NLP LAB”(英国365集团自然语言处理实验室)。
ACL2025(The 63rd Annual Meeting of the Association for Computational Linguistics) 是自然语言处理领域的顶级国际会议之一,由国际计算语言学会(ACL)主办。ACL2025计划在奥地利维也纳线下举行。
论文简介:
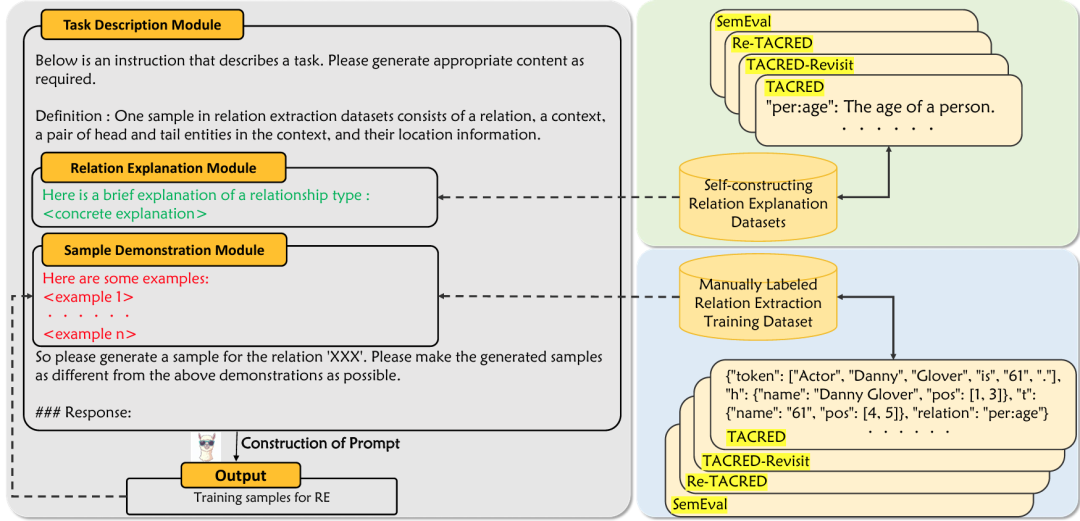
Generating Diverse Training Samples for Relation Extraction with Large Language Models
作者:李泽煊,戴洪良,李丕绩
类型:Long paper, MainConference
摘要:使用大型语言模型(LLMs)生成训练数据是提升零样本或少样本自然语言处理任务的一种可取方法。然而,在这一方向上仍有许多问题有待研究。在关系提取(RE)任务中,我们发现通过直接提示 LLMs 生成的样本很容易在结构上具有高度相似性。在表达一对实体之间的关系时,它们往往采的措辞种类有限。因此在本文中,我们研究了如何有效提高使用 LLMs 生成的 RE 训练样本的多样性,同时保持其正确性。我们首先尝试通过在上下文学习(ICL)提示中直接给出指令,使 LLMs 生成不同的样本。然后我们提出了一种通过直接偏好优化(DPO)来微调 LLMs 以生成多样性训练样本的方法。我们在常用的 RE 数据集上进行的实验表明,这两种尝试都能提高生成的训练数据的质量。我们还发现,与用 LLMs 直接执行 RE 相比,用其生成的样本训练 RE 模型会带来更好的性能。
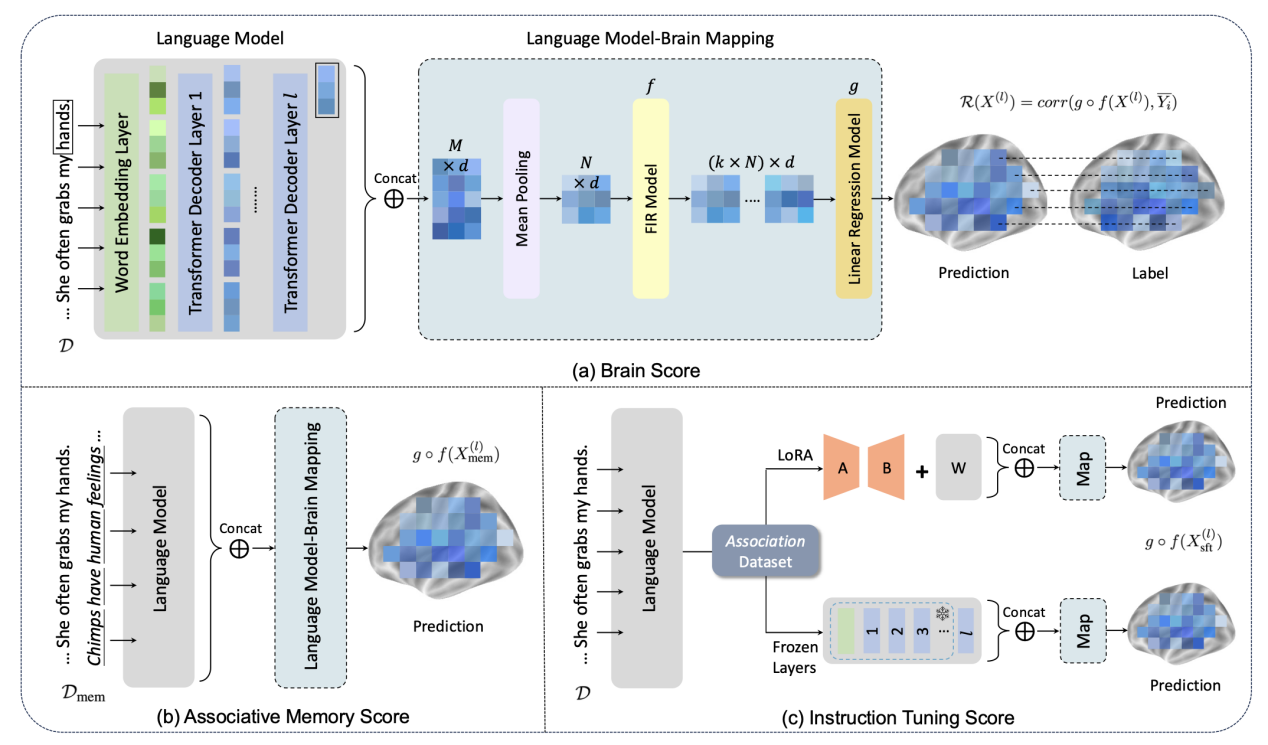
Improve Language Model and Brain Alignment via Associative Memory
作者:殷聪驰,张永朋,温旭云,李丕绩
类型:Long Paper, Findings
摘要:联想记忆在人类认知系统中,参与整合相关信息以实现理解。在这项工作中,我们试图通过整合联想记忆,在处理语音信息时改善语言模型与人脑之间的一致性。在通过将语言模型激活映射到大脑活动来验证语言模型与大脑之间的一致性之后,我们将用模拟联想记忆扩展的原始文本刺激作为计算语言模型的输入。我们发现,在与联想记忆处理密切相关的大脑区域中,语言模型与大脑之间的一致性得到了改善。我们还通过构建 Association 数据集,其中包含1000个故事样本,以及鼓励将联想记忆作为输入和关联内容作为输出的指令,证明了经过特定监督微调的大型语言模型能更好地与大脑反应保持一致。
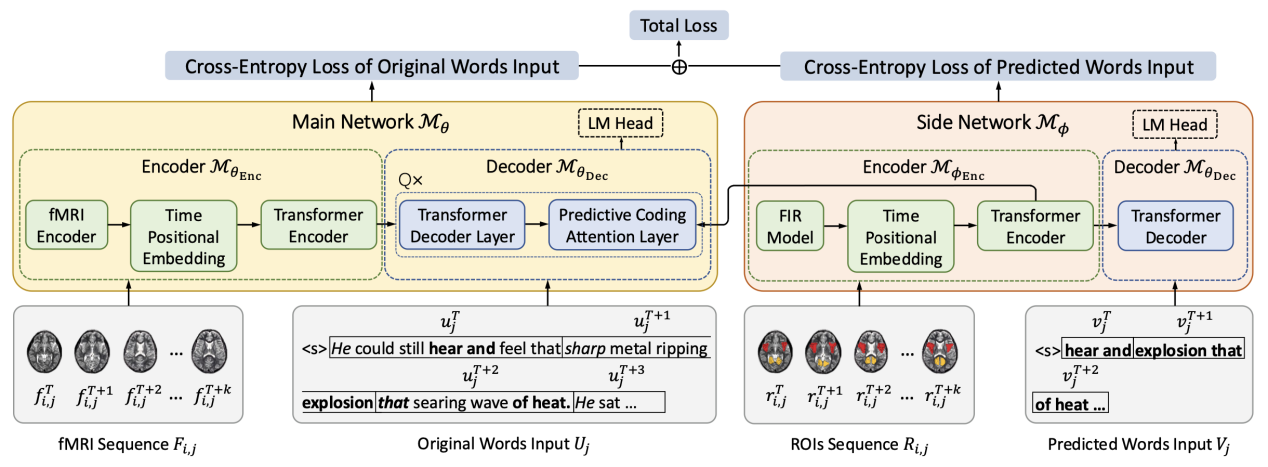
Language Reconstruction with Brain Predictive Coding from fMRI Data
作者:殷聪驰,叶子逸,李丕绩
类型:Long Paper, Findings
摘要:许多最新研究表明,言语感知可以从大脑信号中解码,并随后重建成连续语言。然而,目前缺乏神经学基础来解释如何更有效地利用大脑信号中嵌入的语义信息来指导语言重建。预测编码理论认为,人脑会自然而然地持续预测跨越多个时间尺度的未来词汇。这意味着大脑信号的解码可能与可预测的未来相关联。为了在语言重建的背景下探索预测编码理论,本文提出了PredFT(基于预测编码的fMRI到文本解码)。PredFT 由一个主网络和一个侧网络组成。侧网络通过自注意力模块从相关的感兴趣区域 (ROIs) 获取大脑预测编码表示。然后将该表示融合到主网络中,用于连续语言解码。在两个自然语言理解 fMRI 数据集上进行的实验表明,PredFT在多项评估指标上优于当前的解码模型。